Explanatory Data Analysis group
Research
Our research on Explanatory Data Analysis can be roughly clustered in the four (overlapping) themes described below. Also see the list of concrete research projects and the valorisation examples.
Mining patterns from complex data
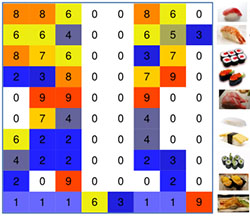
Factorisation.
Patterns are ideally suited to describe and explain structure in data, but traditional pattern mining approaches usually result in too many patterns, and/or are limited to relatively 'simple' data types such as Boolean data. We develop methods for finding pattern-based models that accurately yet succinctly capture the relevant structure in more complex data, such as rank matrices, graphs/networks, and spatiotemporal data. We typically use information theoretic principles to this end, such as the minimum description length (MDL) and maximum entropy principles.
Recent papers that fit this theme include Association Discovery in Two-View Data, Subjective Interestingness of Subgraph Patterns, and Semiring Rank Matrix Factorisation.
Human-guided mining & learning
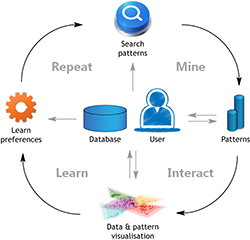
As it is often hard to define upfront which patterns are 'interesting', it can be very helpful to involve the human in the loop. That is, by visualising data and patterns, and by asking the domain expert for feedback, it is possible to learn from the expert's background knowledge and preferences. This can be paraphrased as "Mine, Interact, Learn, Repeat". Human-guided mining and learning aims discover to interesting patterns and models with little effort from the user.
Recent papers include Learning what matters – Sampling interesting patterns, on combining preference learning, pattern mining, and sampling; and Flexible constrained sampling with guarantees for pattern mining, on efficient and flexible sampling.
Interpretable, responsible data science

Responsible data science can be accomplished by addressing the four FACT challenges: Fairness, Accuracy, Confidentiality, and Transparency. Our main focus is on transparency, aiming to establish interpretable learning and mining algorithms that provide interpretable results. One of our approaches is to use the MDL principle for model selection, as this helps to find models that are as simple as possible. Apart from this, we aim to develop privacy-preserving data mining algorithms that help to achieve confidentiality.
We are currently working on several projects in this theme; an existing paper that fits the theme is Explaining Deviating Subsets through Explanation Networks.
Applied data science
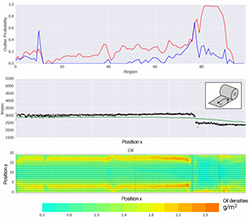
There is no better way to demonstrate the potential of explanatory data analysis than by applying our algorithms and tools to real-world applications. We are interested in both scientific and industrial applications. The scientific application domains we are most experienced with are bioinformatics and psychology, but we are expanding to the health domain and law. We have experience with industrial domains such as aviation, manufacturing, and design simulations.
Recent papers include Towards Data Driven Process Control in Manufacturing Car Body Parts and Simultaneous discovery of cancer subtypes and subtype features by molecular data integration.